Table of Contents
The new Google Search Console shows you what URLs were are causing 404 errors, and not in the index. A static archive of this old Drupal site worked okay, but I needed to redirect old URLs so they’d work again.
They’re Out There, Somewhere
I created static copy of this site, made with wget, roughly in the same way described at drupal.org, Creating a static archive of a Drupal site.
I uploaded it, and it started to work, but recently, saw inside the new search console, this:
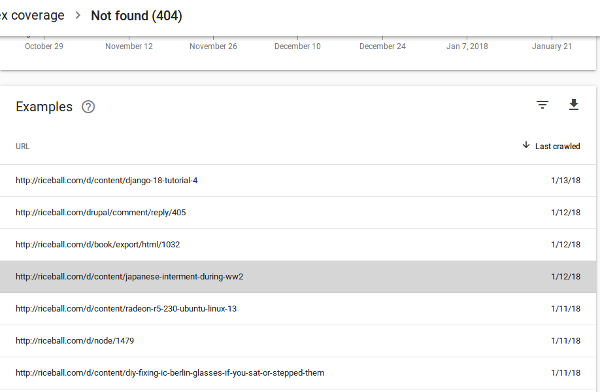
Auuuugh-ah-ah-ah!!! The old site had a zillion URLs that didn’t end in “.html”, while the new archive had only URLs ending in “.html”. So, Google keeps trying these URLs, fails, and then throws it into the “excluded” list.
It’s been crawling these URLs even though they haven’t been working for half a year. I can only guess why it’s doing this: internal links from articles that never got rewritten.
I figured the node/### and content/* URLs are worth saving. Here’s a mod_rewrite configuration that will redirect old URLs to the new archive URLs.
[code]
RewriteRule ^(node/\d+)$ /d/$1.html [L,R=301]
RewriteRule ^(content/[a-z0-9-]+)$ /d/$1.html [L,R=301]
[/code]
Put those into your .htaccess. The rules are read top to bottom, so put those closer to the bottom, and leave the more specific rules up at the top.
What’s Google Going to Do with the 301 Redirects?
Google should follow the redirect, and flow PageRank to the landing page. I think it also helps with site reputation, because there are fewer bad links around.
The other side of it: the crawl budget. It definitely costs more pages from the budget, because a redirect is condered a page, but if Google increases the crawl rate, it’s ok.
Why this Wasn’t Fixed Before
I originally did some manually coded redirects for several popular pages, and let the rest go. Mainly, I hadn’t seen how many bad URLs there were, so figured that only important pages would count. The rest could be re-indexed.
That worked, until I saw the site’s index shrinking, steadily, in 2017. It was probably due to Google excluding duplicate content:
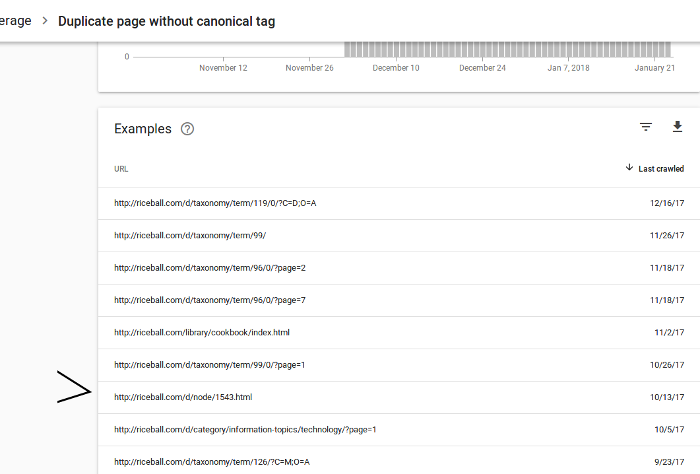
For the most part, I don’t care about those pages, but Google excluded 1543.html, one of the new archive pages.
Google must have seen that new page as a duplicate of d/node/1543, sans “.html”. It did this for three *.html pages, and several pages that didn’t end in “.html”.
So, I guess it’s not that horrible. Google was excluding the old URLs, and keeping the new ones, nearly all the time.
Redirect Old URLs. They’re Out There, Somewhere.
I don’t know why these old links persist, but I’ll assume they are out there, somewhere. I’ve started to find aggregators that just scraped the heck out of my site. They all carry some link juice, so, I’m writing all kinds of rules, and even scripts, to redirect traffic to the article, or to the home page.
Here’s one that I won’t explain too much, but it turns “index.php?q=node/123” queries into 301 relocations, or if the file is gone, returns a 401 GONE status, or shoots them over to the archive index.html page.
[code]
<?php
$q = $_GET[‘q’];
if (preg_match(‘/node\/(\d+)$/’, $q, $matches)) {
$file = $matches[1].".html";
if (file_exists("node/$file")) {
header("Status: 301 Moved Permanently");
header("Location: /d/node/$file");
exit();
} else {
header("Status: 401 Gone");
header("Location: /");
exit();
}
} else if (preg_match(‘/node\/(\d+).html$/’, $q, $matches)) {
// sometimes, q=node/123.html, because the rewrite rule for drupal applies,
// after /node/123 is converted to /node/123.html, but 123.html does not exist.
header("Status: 401 Gone");
header("Location: /");
exit();
}
header("Status: 302 Moved Temporarily");
header("Location: /d/index.html");
[/code]