Table of Contents
The new Google Search Console is awesome. It gives you a lot of details about problems on your site that will harm the Google indexing, and cause pages to be dropped from the index.
That doesn’t mean you want to look at it, and see this:
Google is clamping down on the quality of pages.
I guess I’ll be hacking that site a little bit.
Thursday, February 8
I’ve added rel=”canonical” to links on the printable (.html) and comments versions of the page. There’s also a “tag index” that’s tucked away, but rather than use a canonical URL link, I added a “noindex” metatag to that page.
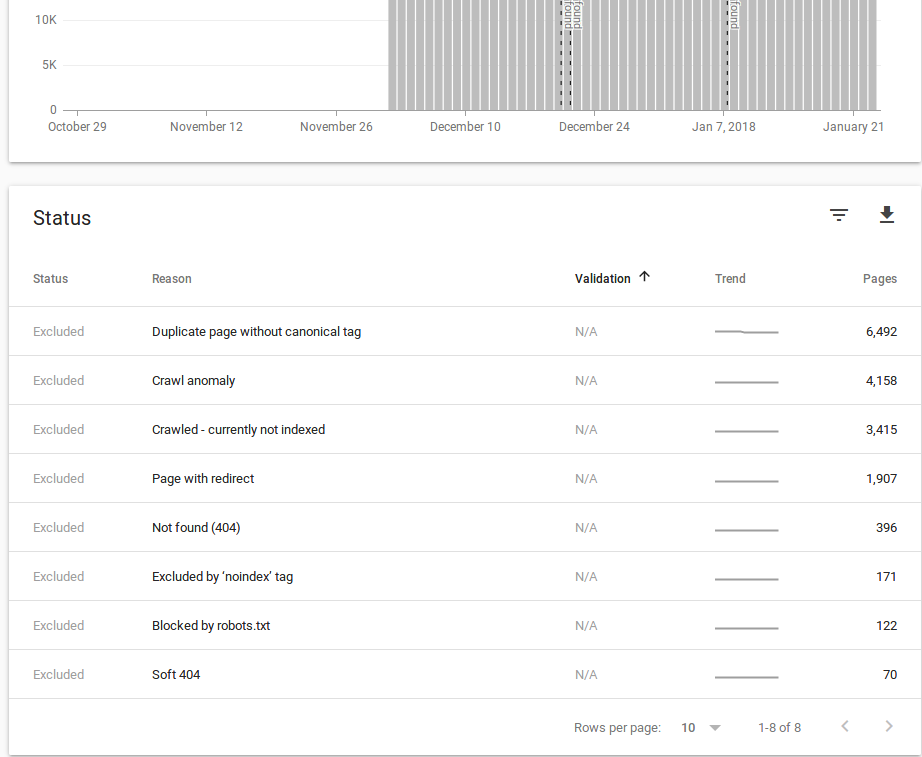
I’ll wait a few days to see what happens to the crawl rate, and if the index cleans out. Today, we have 6,264 pages that are “duplicate page without canonical tag”. 12.3K pages not indexed. 49,850 pages are indexed.
I think we have around 60k pages on the site.
I’m expecting all three numbers to decline, as duplicates are removed. I’m not going to look at search ranking too hard.
Anomalous Pages
There were a bunch of weird links that produced over 4000 crawl anomalies, and I’ll need to fix them. One was a bad link that was on every page of the site. Ooops. That’s gone. Another is a link that may be external to the site, or on an article. I will need to scan all the articles and find relative links, and fix those manually.
If you allow UGC, you must check for bad relative links, because those will point to nonexistent content within your site. It can be as simple as a URL that was typed “example.com/example.html”. That becomes http://yourdomain.com/example.com/example.html.
Many were simple 404 errors for pages that were hidden.
Theme Pages
The site had a weird feature, where you could set the theme of the page with a URL parameter “theme=” and a number. It would end up theme-jacking the user, and I found it annoying. So, after some digging around, figured out how to get rid of that feature, and centralize theme selection on the theme.php page.
Then, next, I went into the Search Console, and told Google that the theme=? parameter doesn’t change the page content. So they will collapse URLs with that parameter into one page.
I’m not sure why these URLs were out there, but they were. I suspect there’s some code in there to enable themes without cookies, and it would just copy the URL parameters onto every single URL.
I also added some code to noindex the themes page. Nobody cares about that page.
Links to Hidden Pages that Were Not Hidden
There’s a feature called “hiding” where the page exists, and can be reached, but is set to noindex, and isn’t linked from other pages on the site. You’d view it with a URL that pointed to hidden.php. There was a subtle problem, where articles that were not hidden could be viewed with this URL. That showed up as an indexed page that was blocked by robots.txt. There’s a noindex tag on there, so it shouldn’t be indexed at all.
I will remove the robots.txt entries, and see what happens to these pages.
Again, I had no idea how these URLS were out there.
I could see these stray URLs being a problem: they could be considered duplicate content.